Using SQLite with Python
David Gilman
LeanTaaS
Pro Football History.com
Why should you use SQLite?
Why should you use SQLite?
It pairs well with Python.
Use the NumPy/Pandas design pattern of moving core data processing to well-tested and optimized C code
Available since Python 2.5 (released 2006)
Why should you use SQLite?
It does a lot for you.
Implementing a query planner, optimizer, executor and B-tree index is hard. Use the experts' code!
SQLite's features set a high bar
When should you use SQLite?
It sets a high bar.
Consider using it as your data's complexity goes beyond Python lists and dicts
Keep using it until you need features, concurrency or speed it doesn't have
It pairs well with Python:
SQLite concurrency model
| Default (Old) | New | |
|---|---|---|
PRAGMA journal_mode=
|
DELETE
|
WAL
|
| Concurrent reader processes | ✔ | ✔ |
| Concurrent writer processes | ✘ | ✘ |
| Reading while writing | ✘ | ✔ |
Why should you use SQLite?
It's an investment in yourself and your career.
Learn the common subset of SQL and relational databases
What you learn with SQLite can be used on future projects, even with different databases
Why should you use SQLite?
It gives you transactions.
Protects you from production bugs like bad data, system failure
Speeds up iterative development
Why should you use SQLite?
It plays nice with other systems.
SQLite is usuable from every language
Distributing data is as easy as copying a file
Why should you use SQLite?
Home team advantage
The author lives in CLT!
Using SQLite and Python together
The basics
import sqlite3
conn = sqlite3.connect("db.sqlite3")
cur = conn.cursor()
with conn:
cur.execute("""
SELECT actor_id, actor_name
FROM actor
WHERE actor_type = ?""", ("Stage",))
for actor_id, actor_name in cur:
print(f"{actor_name} ({actor_id})")
Using SQLite and Python together
Connection.row_factory
Implement your own constructor for query results
sqlite3.Row implements a dict-like interface
A NamedTuple factory isn't hard to implement
Anyone want to contribute a dataclass factory to the standard library?
Using SQLite and Python together
Serializing types
register_adapter: Store Python objects in database
register_converter: Re-hydrate Python objects from the database
Not an ORM
Serializing types
Memoizing the adapter and converter functions is often a speed and memory win in ETL
functools.lru_cache
You can't mutate cached values but that typically isn't a problem
Candidates include datetime, JSON, Decimal
Using SQLite and Python together
Serializing types: datetime
datetime.datetime and date have a default .isoformat() serialization
2012-12-12T12:12:12.123456
Sensible lexicographical ordering and binning (LIKE '2019-01-01%')
Supported by sqlite's (few) datetime functions
Things to know about Python
Serializing types: datetime
Can't do math on a string
Space inefficient
strptime() is slow
Example for adapting datetime to an integer (UNIX timestamp) is in the docs
Things to know about SQLite
Things to know about SQLite
Type affinity
Affinity is how data is stored on disk
Any kind of value can be stored in any column
Column types are just a suggestion on what affinity to use
CREATE TABLE keys (
key_id INTEGER PRIMARY KEY,
email TEXT,
pubkey SSH_PUBLIC_KEY,
privkey SSH_PRIVATE_KEY
);
Things to know about SQLite
B-trees
Table data is kept in a B-tree
The key for a table tree is the rowid
Use INTEGER PRIMARY KEY whenever possible
When no indices are available to aid the evaluation of a query, SQLite might create an automatic index that lasts only for the duration of a single SQL statement. [...]
Things to know about SQLite
Automatic indexing
The query planner can create a temporary index
This can be disabled
Read the logs to find index suggestions
[...] Since the cost of constructing the automatic index is $O(N\log{}N)$ (where $N$ is the number of entries in the table) and the cost of doing a full table scan is only $O(N)$, an automatic index will only be created if SQLite expects that the lookup will be run more than $\log{}N$ times during the course of the SQL statement.
Time complexity, nested for loop
| Big O | Step | a=105, b=105 | a=50, b=105 | a=3, b=105 |
|---|---|---|---|---|
| $O(ab)$ | Loop | 1010 | 106.7 | 105.5 |
Time complexity, index join
| Big O | Step | a=105, b=105 | a=50, b=105 | a=3, b=105 |
|---|---|---|---|---|
| $O(b\log{}b)$ | Index creation | 105.7 | 105.7 | 105.7 |
| $O(a\log{}b)$ | Index join | 105.7 | 250 | 15 |
| Sum | 106.0 | 105.7 | 105.7 |
Time complexity, delta
| Join method | a=105, b=105 | a=50, b=105 | a=3, b=105 |
|---|---|---|---|
| Nested for loop | 1010 | 106.7 | 105.5 |
| Automatic index | 106.0 | 105.7 | 105.7 |
| ✔ | ✔ | ✘ |
The lesson?
$O(n^2)$ sucks!
Things to know about SQLite
Automatic indexing
Up-to-date table statistics helps
The query planner tries different join orders, which helps
This is the SQLite version of a hash join
Where I've used SQLite
CLT Pet Watch Twitter
GitHub

Hybrid fiber-coaxial plant
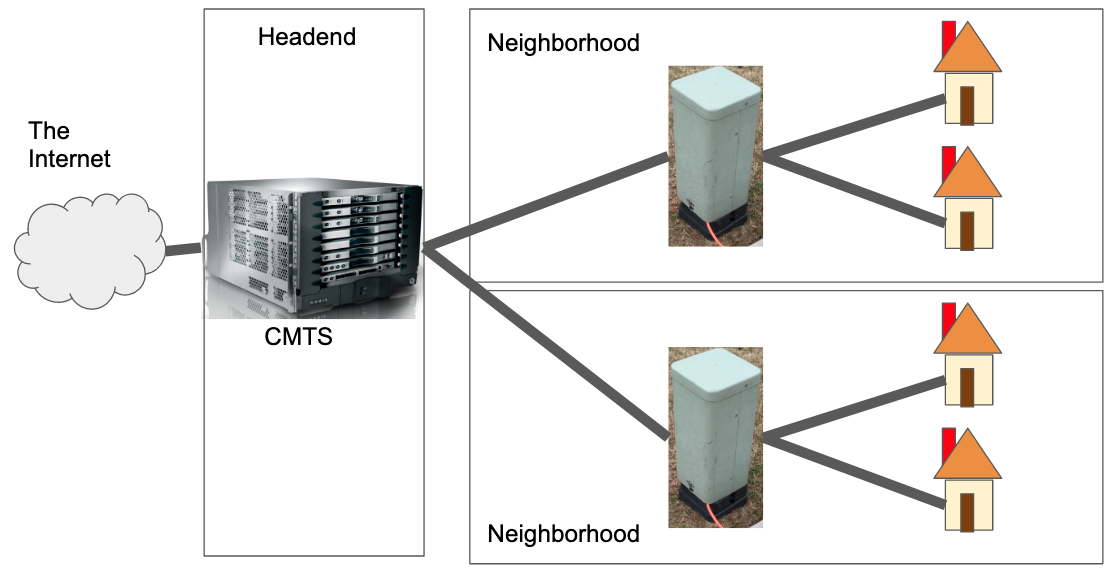
Everything You Always Wanted to Know About Optical Networking – But Were Afraid to Ask: Richard A Steenbergen
Lessons learned porting from SQL Server to SQLite
ETL: Collect and clean up data
Output: Excel
Lessons learned porting from SQL Server to SQLite
Memoization
SQL Server: merge joins and clustered indexes
SQLite: nested for loop joins, materializing joins and subqueries
Lessons learned porting from SQL Server to SQLite
Improvements
A real programming language, in source control
Reliable automation
Many hours faster even if individual parts were slower
openpyxl replaced fragile Excel APIs
Inger
ETL: data collection, parsing, stats
Flask app: runs against the 3NF database
Inger
events.sqlite3: 34GB, 67MM rows of gzipped JSON, 15 minutes to SELECT COUNT(*)
db.sqlite3: 1.2GB, 3NF integers and strings
Inger
Events re-parse
Master API server opens 3NF database
Worker API servers open events.sqlite3
Workers POST their results back to the master server
Inger
Design considerations
JSON and gzip decoding is embarassingly parallel
Primary keys need to be looked up centrally
Heavy cache rates in the workers and bulk inserts